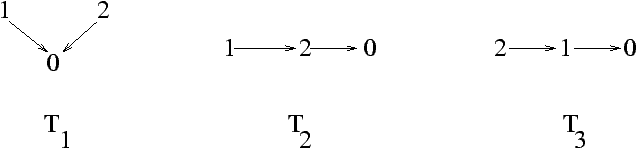
A new formulation of Lagrange inversion for several variables will be described which does not involve a determinant. This formulation is convenient for the asymptotic investigation of numbers defined by Lagrange inversion. Examples of tree problems where the number of vertices of degree k are counted and where vertices are 2-colored will be given. Non-crossing partitions give another example and the Meir-Moon formula for powers of an inversion is a special case.
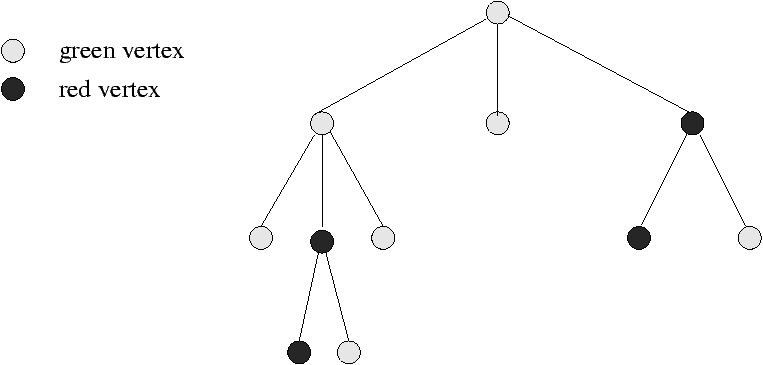
Enumeration of such trees is best done by taking into account the colors of the vertices: let x1 and x2 mark the green and red vertices, and define w1(x1,x2) and w2 (x1,x2) as the functions enumerating the trees whose root is green (resp. red). These functions satisfy the system of equations
| [ xn ] w(x) = |
|
[ tn-1 ] f (t)n; [ xn] g(w(x)) = |
|
[ tn-1 ] g'(t) fn (t) . |
| [ |
|
|
] g( |
|
( |
|
)) = [ |
|
|
] |
æ ç ç ç è |
g( |
|
) |
|
|
( |
|
) |
½ ½ ½ ½ ½ |
½ ½ ½ ½ ½ |
di,j - |
|
½ ½ ½ ½ ½ |
½ ½ ½ ½ ½ |
ö ÷ ÷ ÷ ø |
, |
Now the derivative of a (d+1)-dimensional function f according to such a tree is a product on (d+1) terms, where fi is differentiated according to the incoming edges into the vertex labelled by i; this is best explained on the above example, with f = (f0,f1,f2):1
|
= |
|
· f1 · f2; |
|
= |
|
· f1 · |
|
; |
|
= |
|
· |
|
· f2. |
| [ |
|
|
] g ( |
|
( |
|
)) = |
æ ç ç è |
|
ni |
ö ÷ ÷ ø |
|
[ |
|
|
] |
|
|
, |
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| h:= |
|
+ n2 |
|
|
|
+ n1 |
|
|
|
. |
| k1 = n1 t1 |
|
|
+ n2 t1 |
|
|
; k2 = n1 t2 |
|
|
+ n2 t2 |
|
|
. |
| k1 = n1 |
|
+ n2 |
|
; k2 = n1 |
|
+ n2 |
|
. |
| t1 = |
|
=: r1; t2 = |
|
=: r2. |
| n |
|
|
. |
This document was translated from LATEX by HEVEA.