Results on the performance of binary search trees are usually relative to the random permutation model. This talk presents a randomized version of the insertion and deletion operations on BST that ensures that, whatever the initial distribution of keys, results from the random permutation model apply.
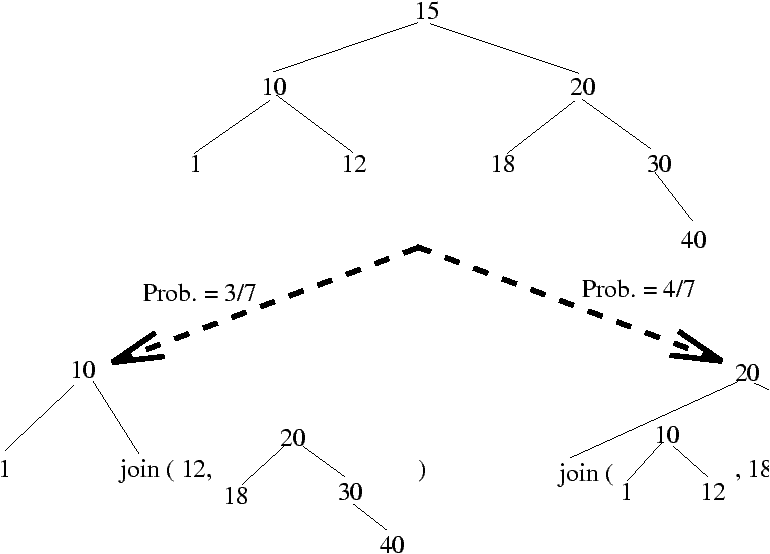
The randomized insertion works as follows
To insert a key X into a BST with n-1 keys, we use the insertion at root algorithm with probability 1/n, and with probability 1-1/n we insert the key recursively into the right or left subtree, according to the respective values of the key and the root.The recursive insertion in a subtree is itself the randomized version; as a consequence, an insertion can happen at any place in the path from the root to the leaf where the key would be inserted if standard insertion were used.
A BST on n keys is random if either it is empty (n=0), or the probability that a given key is at the root is 1/n, and the left and right subtrees are random.This is exactly the BST built under the usual permutation model. The main point in the analysis of randomized BST is to show that insertions or deletions always yield a random BST if applied to a random BST, whatever the key to be inserted or deleted. Once this is done, results on random BST's apply: the average cost of an operation on a randomized BST is O(log n), for any sequence of operations on the tree.
This document was translated from LATEX by HEVEA.