The aim of this work is to design efficient algorithms for string matching. For this purpose, we introduce a new kind of automaton: the factor oracle, associated with the string p to be recognized in a text. This leads to simple algorithms which are as efficient in time as already known ones, while using less memory. This is a joint work with Cyril Allauzen and Maxime Crochemore.
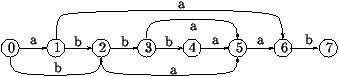
The factor oracle of a word p=p1p2... pm, denoted Oracle(p), is the automaton built by the algorithm Build_Oracle (Figure 1). All the states of the automaton are final. Figure 2 gives the factor oracle of the word p=abbbaab. On this example, the reader will notice that the word aba is recognized whereas it is not a factor of p.
Here are some notations which are used in the following. The set of all prefixes (resp. suffixes) of p is denoted by Pref(p) (resp. Suff(p)). The word prefp(i) is the prefix of length i of p for 0£ i£ m. For any uÎFact(p), we define
| poccur(u,p)=min | { | |z||z=wu and p=wuv | } | , |
http://www-igm.univ-mlv.fr/~raffinot/ftp/IGM99-08.ps.gz.This document was translated from LATEX by HEVEA.