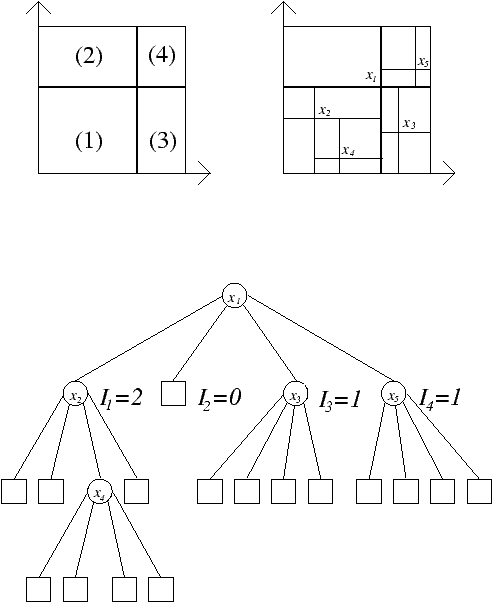
Figure 1: A quadtree: the data partition the unit-cube recursively into quadrants; the quadtree corresponds to this partitioning.
Figure 1: A quadtree: the data partition the unit-cube recursively into quadrants; the quadtree corresponds to this partitioning.
| Cn = 1Y < U |
æ ç ç è |
C |
|
+ C |
|
ö ÷ ÷ ø |
+ 1Y > U |
æ ç ç è |
C |
|
+ C |
|
ö ÷ ÷ ø |
+ 1, |
| E | [Cn] ~ g n |
|
, Var | [Cn] ~ b n |
|
. |
| In/n ® W = | ( | UV,U(1-V),(1-U)V,(1-U)(1-V) | ) |
|
(2) |
|
|||||||||||||||||||
|
| Xn = |
|
. |
| Yn = |
|
Y |
|
+ n. |
| Xn = |
|
|
X |
|
+ Cn(In) |
| Cn(i0,...,i |
|
) = 1 + |
|
|
E | [Y |
|
] - E[Yn]. |
| Cn(i) = 1 + |
|
|
|
ln |
|
+ o(1). |
| Cn = 1 |
|
C' |
|
+ 1 |
|
C'' |
|
+ n - 1 |
This document was translated from LATEX by HEVEA.